---
title: The pgrag extension
subtitle: Create end-to-end Retrieval-Augmented Generation (RAG) pipelines
summary: >-
Covers the setup and usage of the `pgrag` extension for creating end-to-end
Retrieval-Augmented Generation (RAG) pipelines directly within a SQL client,
utilizing Postgres and `pgvector` for efficient information retrieval.
enableTableOfContents: true
updatedOn: '2026-02-06T22:07:32.843Z'
---
What is RAG?
What's included in a RAG pipeline?
`pgrag` functions
How to use `pgrag`
The pgvector extensionYouTube: pgrag video demonstrationpgrag GitHub repository
The `pgrag` extension and its accompanying model extensions are designed for creating end-to-end Retrieval-Augmented Generation (RAG) pipelines without leaving your SQL client. No additional programming languages or libraries are required. With functions provided by `pgrag` and a Postgres database with `pgvector`, you can build a complete RAG pipeline via SQL.
The `pgrag` extension is experimental and actively being developed. Use it with caution as functionality may change.
## What is RAG?
**RAG stands for Retrieval-Augmented Generation**. It's the search for information relevant to a question that includes information alongside the question in a prompt to an AI chat model. For example, "_ChatGPT, please answer questions x using information Y_".
---
## What's included in a RAG pipeline?
A RAG pipeline includes a number of steps, as illustrated in the following diagram.
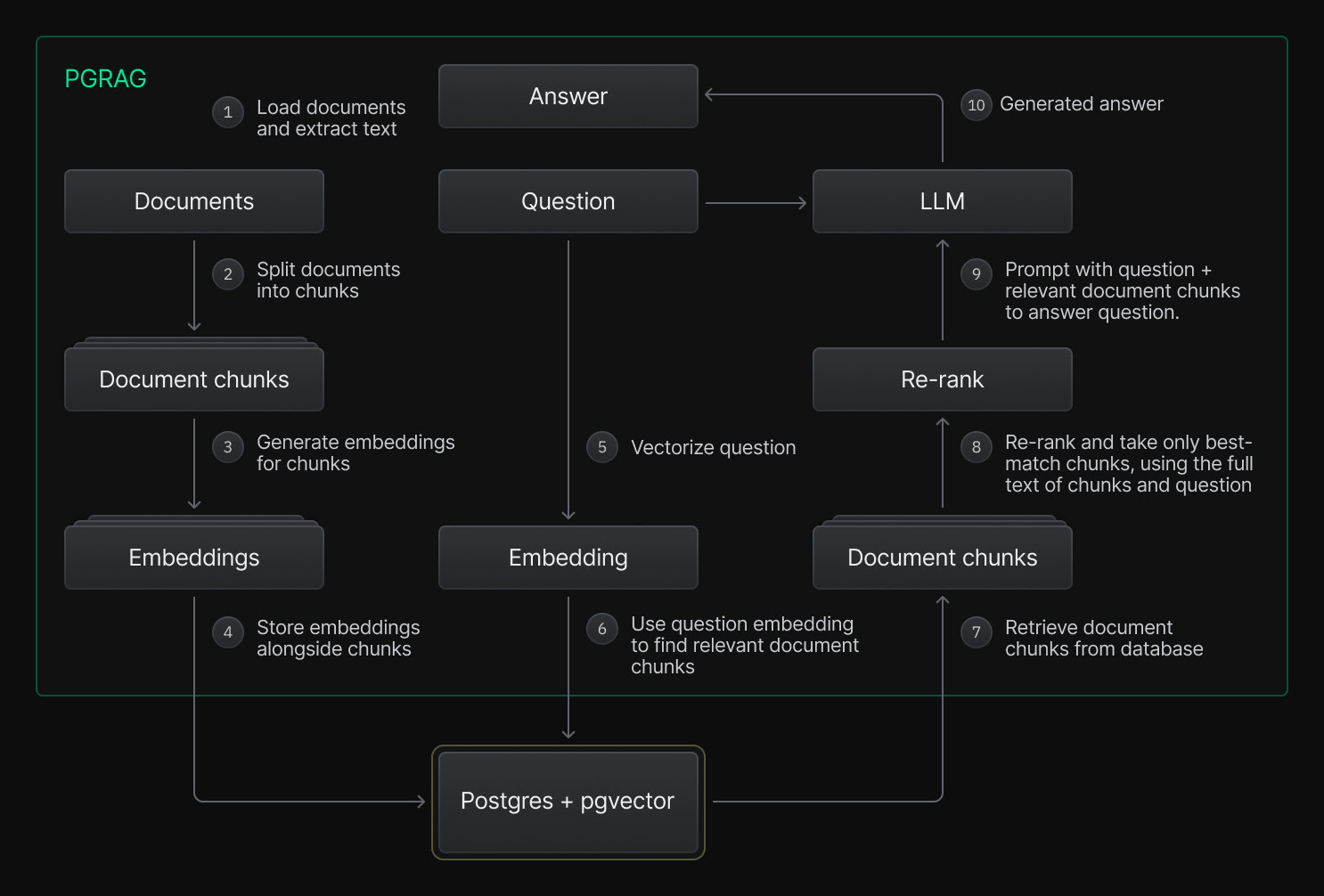
The steps outlined above can be organized into two main stages:
1. **Preparing and indexing the information**:
1. Load documents and extract text
2. Split documents into chunks
3. Generate embeddings for chunks
4. Store the embeddings alongside chunks
2. **Handling incoming questions**: 5. Vectorize question 6. Use question embedding to find relevant document chunks 7. Retrieve document chunks from database 8. Rerank and take only best-match chunks to answer question 9. Prompt with question + relevant document chunks to answer question 10. Generated answer
---
## What does pgrag support?
With the exception of (4) storing embeddings in the database and (7) Retrieve document chunks from database, which is supported by Postgres with `pgvector`, `pgrag` supports all of the steps listed above. Specifically, `pgrag` supports:
- **Text extraction and conversion**
- Simple text extraction from PDF documents (using [pdf-extract](https://github.com/jrmuizel/pdf-extract)). Currently, there is no Optical Character Recognition (OCR) or support for complex layout and formatting.
- Simple text extraction from `.docx` documents (using [docx-rs](https://github.com/cstkingkey/docx-rs)).
- HTML conversion to Markdown (using [htmd](https://github.com/letmutex/htmd)).
- **Text chunking**
- Text chunking by character count (using [text-splitter](https://github.com/benbrandt/text-splitter)).
- Text chunking by token count (also using [text-splitter](https://github.com/benbrandt/text-splitter)).
- **Local embedding and reranking models**
- Local tokenising + embedding generation with 33M parameter model [bge-small-en-v1.5](https://huggingface.co/Xenova/bge-small-en-v1.5) (using [ort](https://github.com/pykeio/ort) via [fastembed](https://github.com/Anush008/fastembed-rs)).
- Local tokenising + reranking with 33M parameter model [jina-reranker-v1-tiny-en](https://huggingface.co/jinaai/jina-reranker-v1-tiny-en) (also using [ort](https://github.com/pykeio/ort) via [fastembed](https://github.com/Anush008/fastembed-rs)).
These models run locally on your Postgres server. They are packaged as separate extensions that accompany `pgrag`, because they are large (>100MB), and because we may want to add support for more models in future in the form of additional `pgrag` model extensions.
- **Remote embedding and chat models**
---
## Installation
As an experimental extension, `pgrag` may be unstable or introduce backward-incompatible changes. We recommend using it only in a separate, dedicated Neon project. To proceed with the installation, you will need to run the following command first:
```sql
SET neon.allow_unstable_extensions='true';
```
To install `pgrag` to a Neon Postgres database, run the following commands:
```sql
create extension if not exists rag cascade;
create extension if not exists rag_bge_small_en_v15 cascade;
create extension if not exists rag_jina_reranker_v1_tiny_en cascade;
```
The first extension is the `pgrag` extension. The other two extensions are the model extensions for local tokenising, embedding generation, and reranking. The three extensions have no dependencies on each other, but all depend on `pgvector`. Specifying `cascade` ensures that `pgvector` is installed.
---
## pgrag functions
This section lists the functions provided by `pgrag`. For function usage examples, refer to the [end-to-end RAG example](#end-to-end-rag-example) below or the [pgrag GitHub repository](https://github.com/neondatabase-labs/pgrag).
- **Text extraction**
These functions extract text from PDFs, Word files, and HTML.
- `rag.text_from_pdf(bytea) -> text`
- `rag.text_from_docx(bytea) -> text`
- `rag.markdown_from_html(text) -> text`
- **Splitting text into chunks**
These functions split the extracted text into chunks by character count or token count.
- `rag.chunks_by_character_count(text, max_chars, overlap) -> text[]`
- `rag_bge_small_en_v15.chunks_by_token_count(text, max_tokens, overlap) -> text[]`
- **Generating embeddings for chunks**
These functions generate embeddings for chunks either directly in the extension using a small but best-in-class model on the database server or by calling out to a 3rd-party API such as OpenAI.
- `rag_bge_small_en_v15.embedding_for_passage(text) -> vector(384)`
- `rag.openai_text_embedding_3_small(text) -> vector(1536)`
- **Generating embeddings for questions**
These functions generate embeddings for the questions.
- `rag_bge_small_en_v15.embedding_for_query(text) -> vector(384)`
- `rag.openai_text_embedding_3_small(text) -> vector(1536)`
- **Reranking**
This function reranks chunks against the question using a small but best-in-class model that runs locally on your Postgres server.
- `rag_jina_reranker_v1_tiny_en.rerank_distance(text, text) -> real`
- **Calling out to chat models**
This function makes API calls to AI chat models such as ChatGPT to generate an answer using the question and the chunks together.
- `rag.openai_chat_completion(json) -> json`
---
## End-to-end RAG example
**1. Create a `docs` table and ingest some PDF documents as text**
```sql
drop table docs cascade;
create table docs
( id int primary key generated always as identity
, name text not null
, fulltext text not null
);
\set contents `base64 < /path/to/first.pdf`
insert into docs (name, fulltext)
values ('first.pdf', rag.text_from_pdf(decode(:'contents','base64')));
\set contents `base64 < /path/to/second.pdf`
insert into docs (name, fulltext)
values ('second.pdf', rag.text_from_pdf(decode(:'contents','base64')));
\set contents `base64 < /path/to/third.pdf`
insert into docs (name, fulltext)
values ('third.pdf', rag.text_from_pdf(decode(:'contents','base64'))));
```
**2. Create an `embeddings` table, chunk the text, and generate embeddings for the chunks (performed locally)**
```sql
drop table embeddings;
create table embeddings
( id int primary key generated always as identity
, doc_id int not null references docs(id)
, chunk text not null
, embedding vector(384) not null
);
create index on embeddings using hnsw (embedding vector_cosine_ops);
with chunks as (
select id, unnest(rag_bge_small_en_v15.chunks_by_token_count(fulltext, 192, 8)) as chunk
from docs
)
insert into embeddings (doc_id, chunk, embedding) (
select id, chunk, rag_bge_small_en_v15.embedding_for_passage(chunk) from chunks
);
```
**3. Query the embeddings and rerank the results (performed locally)**
```sql
\set query 'what is [...]? how does it work?'
with ranked as (
select
id, doc_id, chunk, embedding <=> rag_bge_small_en_v15.embedding_for_query(:'query') as cosine_distance
from embeddings
order by cosine_distance
limit 10
)
select *, rag_jina_reranker_v1_tiny_en.rerank_distance(:'query', chunk)
from ranked
order by rerank_distance;
```
**4. Feed the query and top chunks to a remote AI chat model such as ChatGPT to complete the RAG pipeline**
````sql
\set query 'what is [...]? how does it work?'
with ranked as (
select
id, doc_id, chunk, embedding <=> rag_bge_small_en_v15.embedding_for_query(:'query') as cosine_distance
from embeddings
order by cosine_distance
limit 10
),
reranked as (
select *, rag_jina_reranker_v1_tiny_en.rerank_distance(:'query', chunk)
from ranked
order by rerank_distance limit 5
)
select rag.openai_chat_completion(json_object(
'model': 'gpt-4o-mini',
'messages': json_array(
json_object(
'role': 'system',
'content': E'The user is [...].\n\nTry to answer the user''s QUESTION using only the provided CONTEXT.\n\nThe CONTEXT represents extracts from [...] which have been selected as most relevant to this question.\n\nIf the context is not relevant or complete enough to confidently answer the question, your best response is: "I''m afraid I don''t have the information to answer that question".'
),
json_object(
'role': 'user',
'content': E'# CONTEXT\n\n```\n' || string_agg(chunk, E'\n\n') || E'\n```\n\n# QUESTION\n\n```\n' || :'query' || E'```'
)
)
)) -> 'choices' -> 0 -> 'message' -> 'content' as answer
from reranked;
````